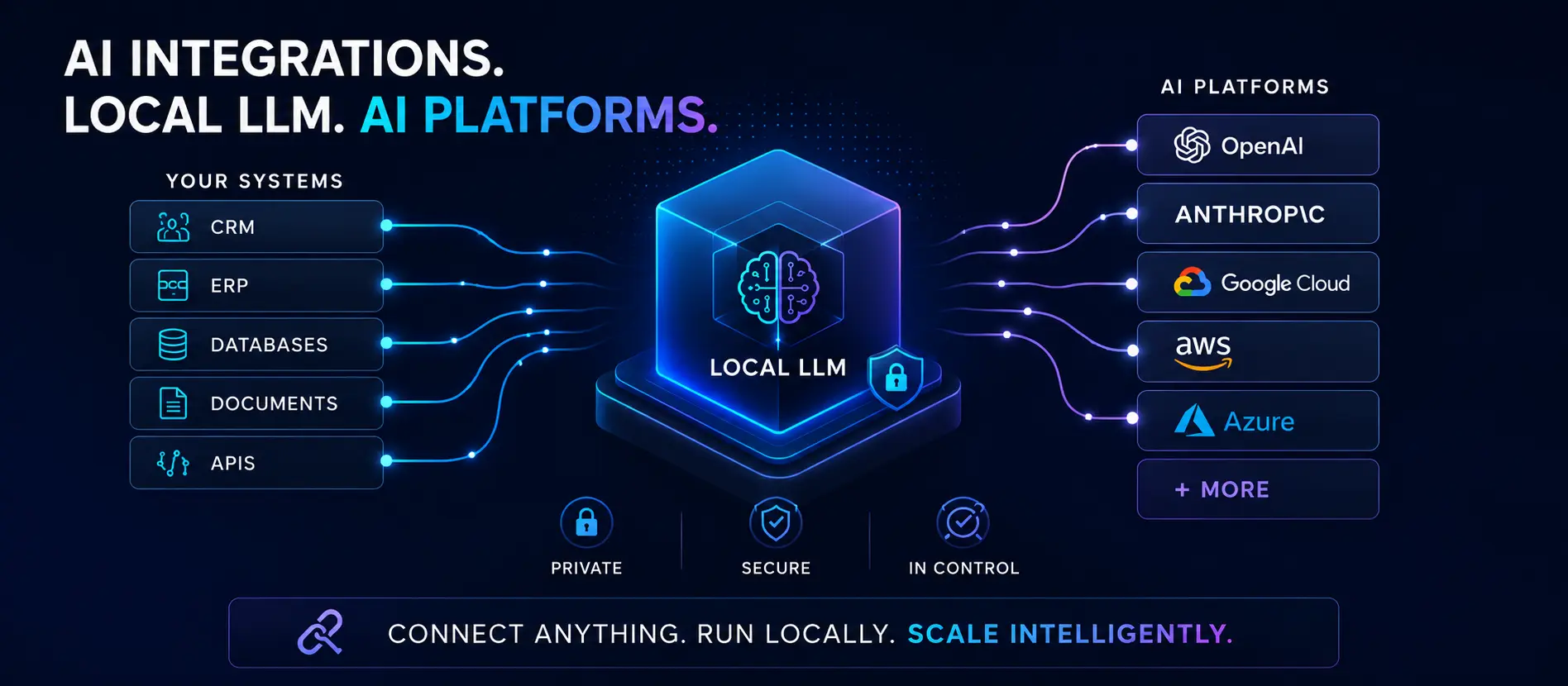
North Carolina AI integration services built for small businesses across the Piedmont Triad — local LLMs and cloud AI platforms adding assistants, semantic search, RAG pipelines, and content generation while keeping your data private, on-premises, and under your control. Ready to automate workflows around your AI? See our Agentic Systems & Automation services.
Local LLM deployment (Ollama) RAG & vector search Cloud API integrations Zero data leaves your network
Six Ways AI Gets Integrated
Every engagement starts with your use case — then we pick the right architecture. These are the six most common patterns deployed for small and medium businesses.
Local LLM Deployment
Run Mistral, Llama, Gemma, Qwen, and other open-weight models on your own hardware or internal server using Ollama. Zero API costs, complete data privacy, sub-100ms inference.
Cloud API Integrations
Connect your app or website to OpenAI, Anthropic, Google Gemini, or open-weight hosted APIs through clean, versioned wrappers — with proper error handling, rate limiting, and fallback logic.
RAG Pipelines
Retrieval-Augmented Generation connects LLMs to your own documents, knowledge bases, and internal databases so answers are grounded in your real data — not hallucinations.
Semantic Search
Replace keyword search with vector-based similarity search using text embeddings and a local or cloud vector database (pgvector, Qdrant, Chroma). Find meaning, not just matching words.
AI Assistants
Conversational assistants embedded in your website, app, or internal tool — trained on your content, brand voice, and FAQs. Works with local or cloud models depending on your privacy needs.
Content Generation
Automated content workflows for product descriptions, summaries, email copy, and reports — with structured prompts, human-review checkpoints, and output validation built in.
AI Integration Packages
Fixed-scope engagements with clear deliverables, full source code handoff, and documentation on every project.
AI Starter
Connect your app or site to a cloud AI API — first AI feature, fast and clean.
$1,500–$3,500
1–3 week delivery · One-time project
API integration (OpenAI, Anthropic, Gemini, or equivalent)
One AI feature: assistant, content generation, or classification
AI systems need maintenance — models update, prompts drift, and usage patterns change. Retainers keep your integration healthy and compounding over time.
AI Monitor
Monthly health check — model performance, API reliability, and usage reporting.
Every AI integration follows the same four-phase process — requirements first, then architecture, then build, then handoff.
1
Discovery & Requirements
Understand your use case, data sources, privacy requirements, and existing stack. Define the integration scope, model candidates, and success criteria before writing a line of code.
2
Architecture Selection
Choose between local LLM, cloud API, or hybrid. Select the right model for your use case, design the prompt schema, define the data pipeline, and map the integration points to your existing app or website.
3
Build & Integrate
Build the integration incrementally with review checkpoints. You get a working demo at each milestone — not a big reveal at the end. All code is yours, no vendor lock-in.
4
Test, Deploy & Document
End-to-end testing, performance benchmarking, deployment to your environment, and full handoff documentation including a runbook so your team can operate and extend the system.
À La Carte Services
Need one specific piece rather than a full package? These standalone services are available individually or as add-ons to any existing project.
LLM API Integration
Connect one app or endpoint to a commercial AI API with clean implementation.
$500–$1,500
Single API integration (OpenAI, Anthropic, Gemini, etc.)
AI isn't just for tech companies. These are the most common integrations built for small and medium businesses in 2025–2026.
Customer Support Assistant
Answer FAQs, pull from your knowledge base, and hand off to a human when needed — available 24/7, no extra staff.
Internal Knowledge Search
Search across PDFs, wikis, and internal docs using natural language — employees find answers in seconds, not hours.
Product Description Generator
Feed in specs, get polished, on-brand product descriptions at scale — consistent tone, no copywriter bottleneck.
Intake & Triage Assistant
Classify incoming requests, extract key fields, and route them to the right team or workflow — before a human even reads it.
Report Summarizer
Upload long reports, meeting transcripts, or data exports and get concise, structured summaries your team can act on immediately.
Multilingual Content
Translate and localize marketing copy, product pages, or support content at a fraction of the cost of professional translation agencies.
Why Build with Conxion Visual Communications Instead of a Big AI Agency?
Enterprise AI shops charge for team overhead and vendor relationships you don't need. You get direct access to the person building the system — and own everything when it's done.
Agency / Platform Drawbacks
Conxion Visual Communications Advantage
❌ $10,000–$50,000+ for local LLM setups at enterprise firms
✅ Private LLM Deploy from $3,500 — same capability, SMB-priced
❌ Ongoing per-token API costs that compound as usage grows
✅ Local deployments = zero ongoing API costs — your hardware, your model
❌ Your data leaves your network every time you call a cloud API
✅ Local LLM keeps all data on-premises — nothing sent to third-party servers
❌ "Black box" integrations — no code access, no portability
✅ Full source code handoff — you own everything, no vendor lock-in
❌ Generic implementations not tailored to your actual use case
✅ Built around your data, your stack, and your workflow
❌ Account managers relay feedback through layers
✅ Direct access — you talk to the builder, not a project coordinator
Privacy-first architecture
Local LLM deployments keep every query, document, and response inside your network. Nothing leaves your premises — ever.
Full code ownership
Every integration is delivered as clean, documented source code. You can extend it, hand it to another developer, or run it forever — no subscriptions, no lock-in.
Pragmatic model selection
The best model for your use case isn't always the biggest or most expensive. We benchmark 3–5 candidates against your actual tasks before recommending one.
Design + build in one place
Need an AI assistant embedded in a new website? The UI design, front-end build, and AI integration all come from the same person — no coordination overhead.
Flexible Hourly Rate
Need a quick integration audit, a model recommendation, or a one-off consultation before committing to a package? I offer flexible hourly engagements — no minimum, no retainer required.
Common questions about AI integrations, local LLMs, and how these projects work.
A cloud API (like OpenAI) sends your prompt data to a third-party server, incurs a per-token cost, and requires an internet connection. A local LLM runs the model on hardware you own — nothing leaves your network, there are no per-token fees once it's deployed, and latency is often lower. The trade-off is that local models typically require capable hardware and occasional maintenance, whereas cloud APIs scale automatically. For privacy-sensitive workloads or high query volumes, local deployment usually wins. For quick integration or variable usage patterns, cloud APIs can be the better fit.
It depends on the model size and query volume. For most SMB use cases — internal assistants, document search, classification — a workstation or server with a mid-range NVIDIA GPU (8–24 GB VRAM) running a 7B–13B parameter model is sufficient and costs $800–$2,500 new. If you already have suitable hardware, you may need zero additional investment. As part of any local LLM engagement, we'll benchmark your current hardware before recommending whether to use it, upgrade it, or select a smaller model that fits what you already have.
For local deployments: Llama 3, Mistral, Mixtral, Gemma, Qwen, Phi, and others served through Ollama. For cloud APIs: OpenAI (GPT-4o, o4-mini), Anthropic (Claude), Google Gemini, and open-weight hosted options like Together AI or Fireworks AI. Model selection is always use-case-driven — we benchmark 3–5 candidates against your actual tasks rather than defaulting to whatever is currently trending.
Yes — most integrations are added to existing systems rather than built from scratch. A chat assistant, semantic search widget, or content generation endpoint can typically be added to any website or app regardless of its stack or age, as long as it has the ability to make HTTP requests or embed a script. The discovery call at the start of every project maps your current stack to the integration approach that fits it best.
The safest option is a local LLM deployment where no data ever leaves your network. If cloud APIs are used, sensitive fields can be redacted or anonymized before the prompt is sent, and results re-enriched on the way back. API provider data-handling policies (OpenAI's Enterprise tier, Anthropic's API) can also be configured for zero data retention. Every engagement includes a data flow diagram so you can see exactly where your information goes at each step.
Yes — all AI integration work is done remotely by nature. Requirements gathering, reviews, and handoff all happen via video call, email, and shared documents. For local LLM setups that involve physical hardware, remote installation via SSH or VPN is the standard approach; an in-person visit can be arranged for clients in the Piedmont Triad area.
Ready to Add AI to Your Business?
Let's start with a free consultation — I'll review your use case and recommend whether a local LLM, cloud API, or hybrid approach makes the most sense for your budget and privacy requirements.