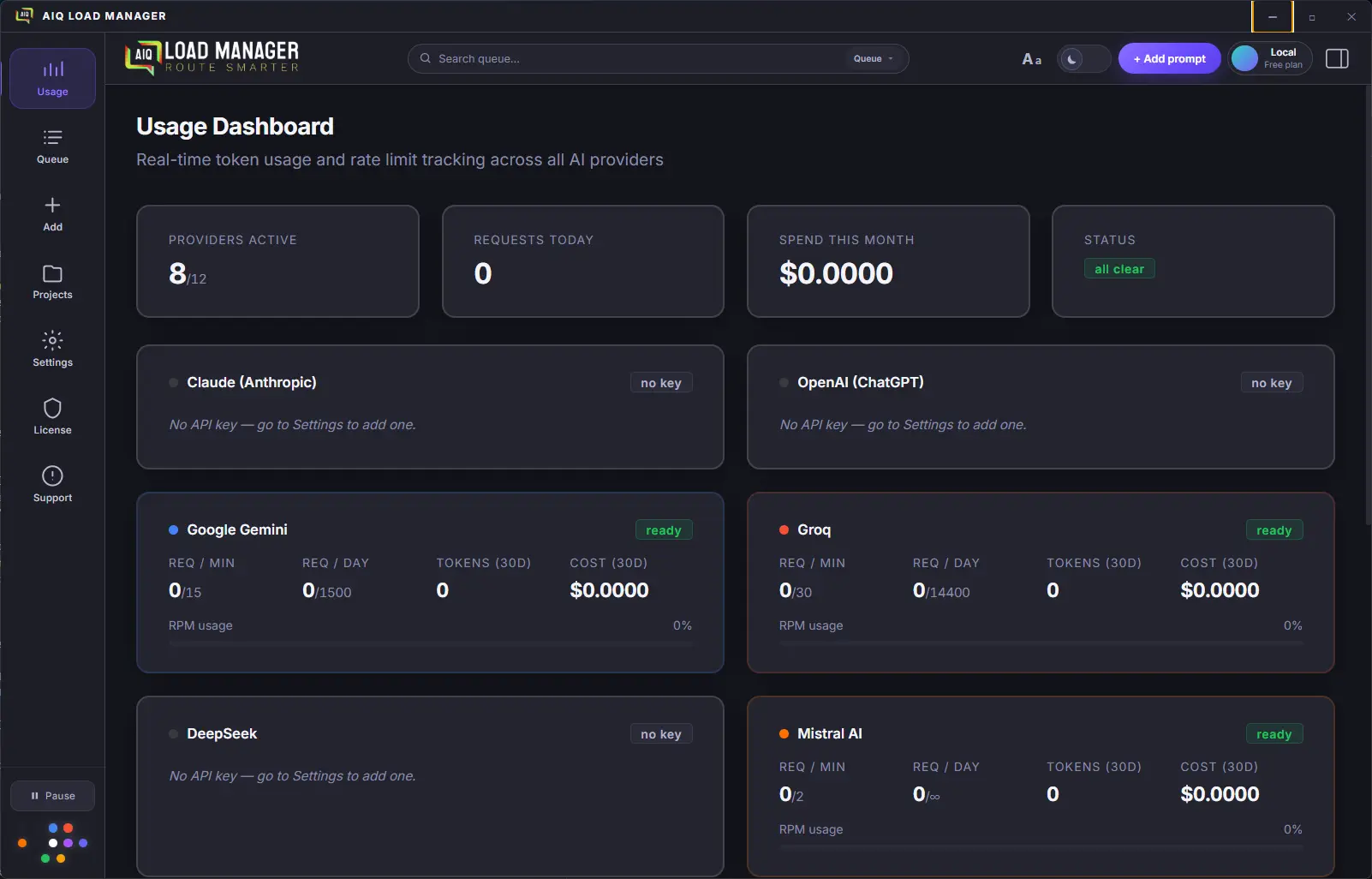
The full desktop app on Linux — AppImage format runs on any distro
without installation or root access, plus a .deb package for
Debian and Ubuntu users. The electron-builder config
is already in place. Needs a round of testing on a Linux CI runner
before public release. All features parity with Windows and macOS.
When the router re-routes a conversation to a different provider
mid-thread — because of rate limits, cost, or availability — the
stored history is automatically adapted to the new provider's
format and forwarded. Your conversation keeps going, invisibly. No
other tool can do this, because no other tool routes across
providers in the first place.
A tier above Pro for power users who need the full stack:
Consensus mode, advanced prompt chaining, webhook output delivery,
and priority support. Designed for teams and high-volume
workflows. Details and pricing TBD.
Compare mode already collects every provider's response in one
place. Consensus mode goes further: a meta-model synthesises the
best answer from all of them, flags where providers disagree, or
runs a majority-vote across outputs. One click from Compare — no
separate queue, no extra setup.
Save reusable prompt templates with named variables. Fill in the
blanks and queue — no copy-paste gymnastics.
Use the output of one queue item as the input to the next. Build
multi-step AI pipelines without writing code.
Upload a CSV of prompts and queue them all at once. Ideal for bulk
content generation, testing, or data processing workflows.
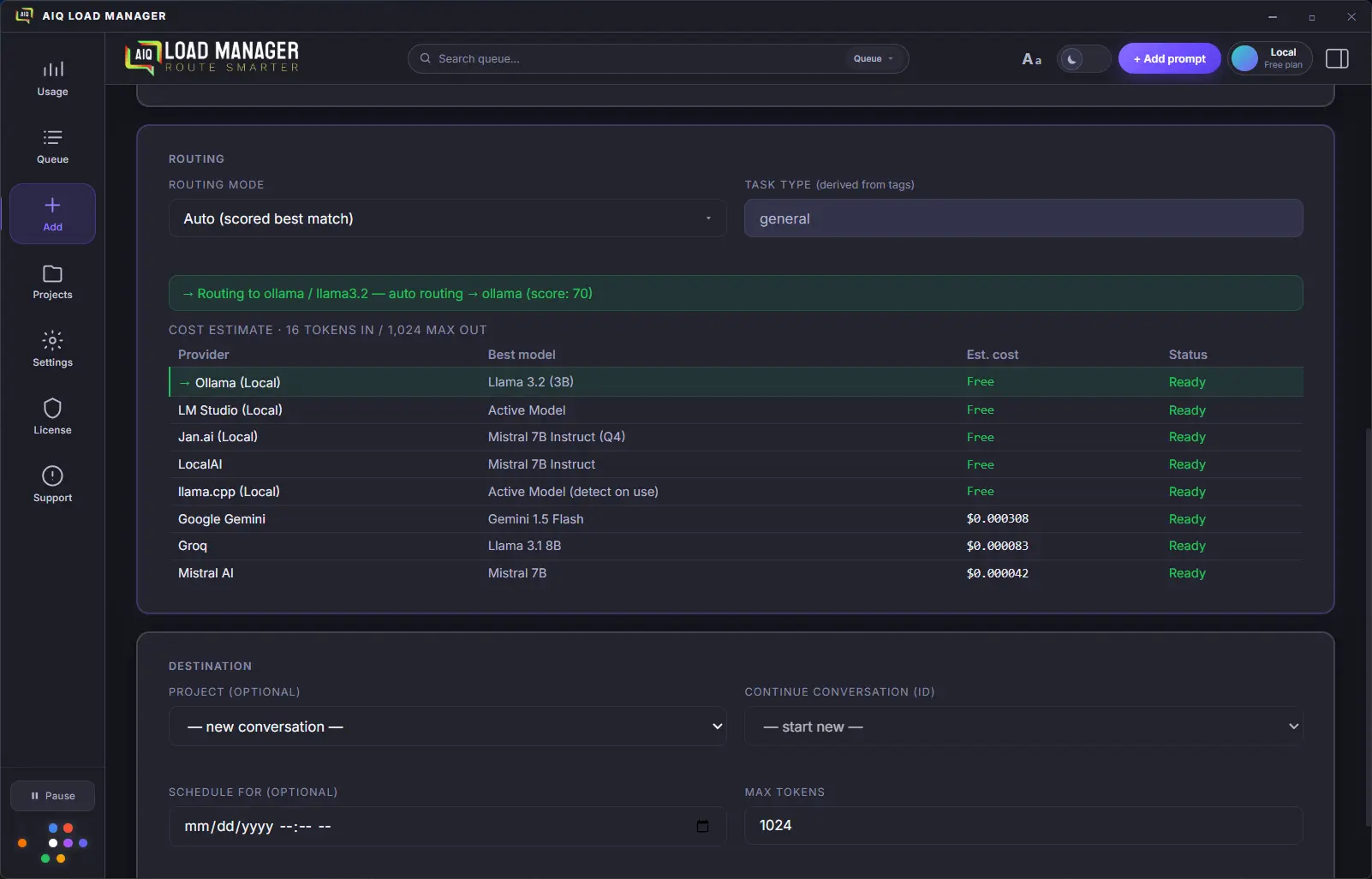
Define cost and model threshold rules that override the automatic
routing decision — for example: "never use Claude if estimated
cost exceeds $0.02" or "always route Code prompts to GPT-4o".
Builds on top of the existing 6 routing modes without replacing
them.
Export raw usage data — token counts, costs, timestamps, provider
and model — as CSV on Starter or CSV + JSON on Pro and above.
Distinct from the session digest HTML export, which is a formatted
report. Useful for importing into spreadsheets or external
analytics tools.
Queue image prompts to DALL-E 3, Flux, Ideogram, and Stable
Diffusion (locally via ComfyUI — free). Each image is a queue
item. Batch-generate dozens while you work on something else.
Results auto-save to a folder you choose. Same routing and
cost-tracking model you already know.
The queue model is tailor-made for video AI. Runway, Pika, and
Kling take 2–10 minutes per clip and cost real money — exactly
when a managed queue with per-job cost tracking earns its keep.
Submit a batch, walk away, come back to finished clips ready to
download.
POST completed responses to any URL the moment they're ready.
Connect AIQ to Zapier, Make, or your own backend without polling.
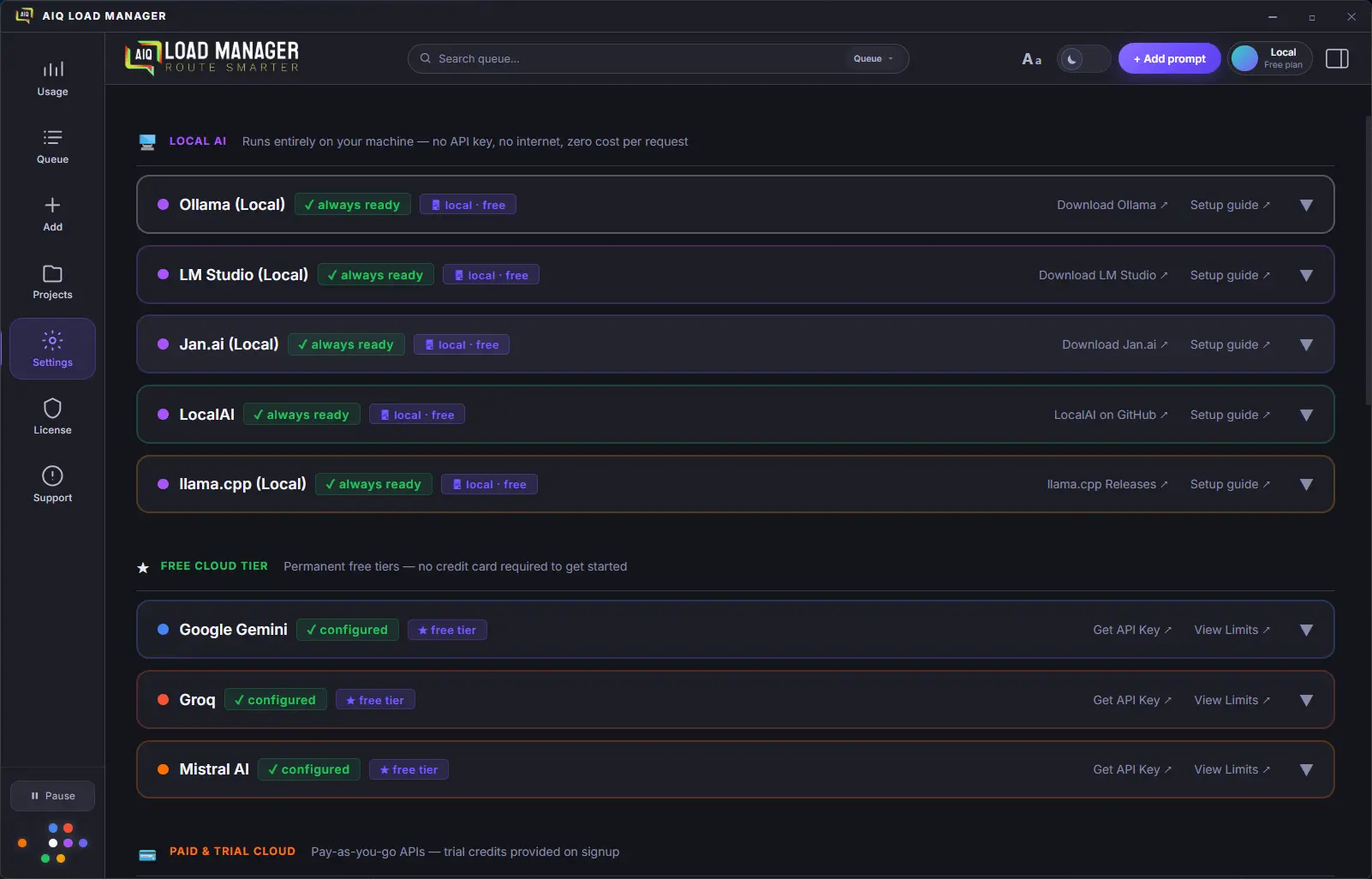
Run any model locally via Ollama, LM Studio, Jan.ai, LocalAI, or
llama.cpp. Zero API cost, complete privacy, fully offline. Models
are discovered automatically — Llama, Mistral, Phi, Gemma, Qwen,
DeepSeek-R1 and more. All server ports are configurable.
v0.7.0 adds a Local / Network toggle so
you can connect to a model running on another machine on your LAN
or over VPN — no localhost required.
All 7 use the existing OpenAI SDK — no new npm packages needed.
Phase 1 · v0.6.0 —
Fireworks AI (fastest inference,
Llama/DeepSeek/Qwen) · Together AI (200+
open-source models, $25 free credit) ·
Cerebras (wafer-scale speed, ~1,800 tok/s, free
tier) · MiniMax (MiniMax M3 — GPT-4o quality at
$0.60/M input) · Cohere (enterprise
instruction-following, trial key)
Phase 2 · v0.7.0 —
Perplexity AI (search-grounded responses with
live web citations embedded in every reply)
Phase 3 · v0.8.0 —
OpenAI Codex (dedicated coding agent; reuses your
existing OpenAI key — zero extra setup)
Pro+ removes the 500-item queue soft cap entirely, raises cloud
limits to 10,000 prompts and 20M tokens per month, adds Consensus
mode (meta-model synthesis across Compare results), and includes
priority email support. Built for solo power users who outgrow Pro
without needing team features.
Attach local files — PDF, DOCX, TXT — as persistent context for a
project. The file content is injected into the system prompt for
every prompt in that project. Nothing leaves your machine: files
are read locally and never uploaded to any server.
Schedule automated email digests of your completed session
activity — daily or weekly. Free and Starter users can already
export session digests as local HTML files; Pro+ adds email
delivery so you receive a formatted summary without opening the
app.
Predict your monthly AI spend based on current usage trends. Get
warned before you blow a budget, not after.
Queue prompts from your phone, receive push notifications on
completion, monitor live costs. Included with Starter and Pro at
no extra charge.
A week/month grid that shows all your upcoming scheduled queue
items as visual blocks — click any item to preview, edit, or
cancel it, and drag to reschedule. Pairs with the usage heatmap
below to give you a unified past/forward view of everything in
your queue, laid out on a timeline instead of a flat list.
A new Insights sidebar panel powered entirely by your existing
local SQLite data — no new infrastructure needed. Shows
time-series charts of prompts/day, cost/day, and tokens/day;
provider and model distribution; tag-type breakdown; and a
busiest-hours heatmap so you can see exactly when and how you're
using each provider.
A GitHub-style contribution graph showing prompt volume and cost
by day over the last 90 days. Lives inside the Insights panel
alongside the scheduled-items calendar, giving you one place to
see your full AI usage history at a glance — dark squares mean
high-activity days, colours shift from tokens to cost.
Pattern observations that surface concrete routing efficiency
suggestions based on your actual usage history — for example: "You
route 90% of Research prompts to Claude, but Gemini costs 4× less
for that tag type." Runs entirely against local SQLite data; no
prompt content is analysed externally or sent anywhere.
A local model (Ollama or LM Studio) reviews your prompt patterns
and suggests rewrites and routing changes that cut cost or improve
output quality. Requires a local provider to be configured.
Because analysis runs on your own hardware, no prompt content ever
leaves the machine — the optimization is completely private.
AIQ spins up a local HTTP server (localhost:8787)
that speaks the standard OpenAI Chat Completions API. Any AI agent
framework — Hermes, OpenClaw, n8n, LangGraph, CrewAI, AutoGen,
OpenAI Agents SDK — can point its
base_url at AIQ and instantly inherit AIQ's full
routing, rate-limit management, cost tracking, and provider
fallback. No code changes on the agent side. Pass
aiq/auto, aiq/cheapest, or
aiq/fastest as the model name to invoke routing
modes, or pass any real model name to force a specific provider.
Streaming (stream: true) is fully supported. A new
Gateway panel shows server status and a live request log.
Also ships with OpenRouter as a new provider —
500+ models through a single API key, using the same
OpenAI-compatible SDK already in the app.
Replaces binary UP / DOWN status with a rolling
composite score per provider: latency (p50 & p95), error
rate %, token throughput (tokens/sec), and RPM headroom. Each
provider card in the Usage Dashboard shows a live gauge. The
router uses the score for weighted decisions in
auto mode — so a fast-but-unreliable provider scores
lower than a slightly slower but rock-solid one.
Tokens/sec and average response time displayed per provider in the
Usage Dashboard — no new backend needed, derived from existing
queue completion events. Cerebras and Groq are the showcase:
seeing "Cerebras ~1,800 tok/s vs.
GPT-4o ~45 tok/s" live makes the
fastest routing mode instantly tangible.
Scope a monthly USD budget to a project rather than to a single
provider. The cap spans all providers the project uses, so "this
client gets $50/month of AI" works regardless of which provider
processes each item. Pairs with cost tracking and usage export for
a complete per-project cost picture.
A live cost/quality scoring engine that extends the existing
cheapest mode and custom routing rules. Define
thresholds like "max $0.03/request" or "never use Claude for Chat
prompts" and the router enforces them at dispatch time,
dynamically selecting the cheapest provider that meets all active
rules. The cost table updates live as provider pricing changes —
few competitors do this well.
Define per-project SLA rules — maximum latency, maximum cost per
request, minimum reliability score. When the winning provider
fails an SLA check, the router falls back to the next-best
provider automatically, with no user intervention. Rules are
stored locally per project. This is the "Cloudflare for AI
inference" differentiator — no other desktop tool enforces SLAs
across providers.
An append-only local log of every routing decision: which item
went where, which routing mode fired, which rule matched, and what
it cost. Stored in SQLite alongside existing usage data — no new
infrastructure. Gives governance-conscious users full
accountability and is the foundation for a compliance reporting
tier later.
Connect local AI providers (Ollama, LM Studio, Jan.ai, LocalAI,
llama.cpp) to a model running on any machine on your network — a
home server, a more powerful workstation, or a remote host over
VPN. Each provider card gets a
Local / Network toggle: Local locks to
localhost (zero-config, unchanged today); Network
lets you enter the host and port, shows the correct setup hint for
that tool, and displays the full constructed URL. A built-in
Test Connection button pings the server and
confirms models are reachable before you save.
Assign a cost-center label — client, department, or team — to any
project. Usage exports include the cost-center field so you can
generate per-client or per-department spend reports in your own
spreadsheet or BI tool. Enables chargeback billing for MSPs and
freelancers without requiring a full billing engine.
Route agentic task payloads — OpenAI Agents, LangGraph, CrewAI,
MCP tool calls — through the queue the same way text prompts are
routed today. The queue model already handles async workloads with
retry, cost tracking, and provider fallback; this extends it to
multi-step agent runs. An emerging market with very few tools
doing it well.